一、概述
Apache Spark是一种快速和通用的集群计算系统。它提供Java,Scala,Python和R中的高级API,以及支持一般执行图的优化引擎。它还支持一组丰富的更高级别的工具,包括Spark SQL用于SQL和结构化数据的处理,MLlib机器学习,GraphX用于图形处理和Spark Streaming。
Spark除了在Mesos或YARN群集管理器上运行,它还提供了一种简单的独立部署模式Standalone模式。接下来我们就以下面的WordCount代码为例剖析Spark Standalone模式的运行原理。理解并掌握Spark Standalone模式的运行原理对后期进一步学习Spark相关技术有很大的帮助,同时也是Spark开发工程师岗位面试经常被提问的地方。
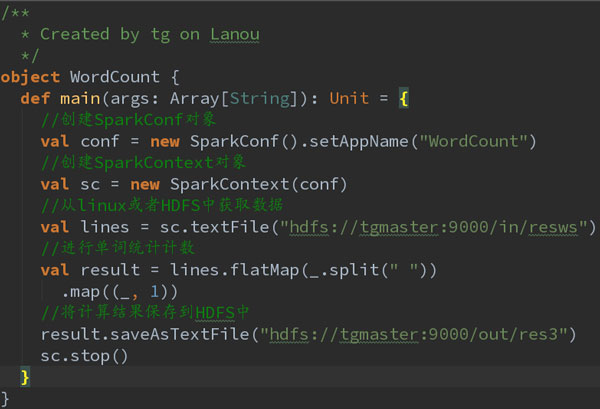
WordCount代码如下:
Standalone运行模式原理概要如下图所示:
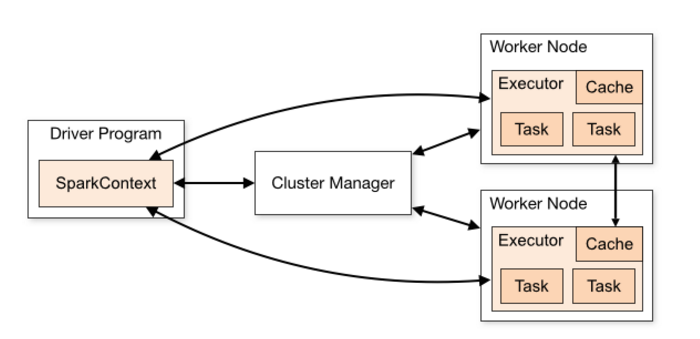
二、Standalong模式运式原理剖析之天龙八“步”
1、第一步:
通过spark-submit指令将打好的Spark jar包提交到Spark集群中运行。先从Driver进程开始运行,Driver中包含了我们所编写的代码。
首先执行代码中的前两行代码,
//创建SparkConf对象
val conf = new SparkConf().setAppName("WordCount")
//创建SparkContext对象
val sc = new SparkContext(conf)
这两行代码分别创建了SparkConf和SparkContext对象,在创建SparkContext对象的过程中,Spark会去做两件很重要的事,就是创建DAGScheduler和TaskScheduler这两个对象。然后,TaskScheduler会通过一个后台进程负责与Master进行注册通信,告诉Master有一个新的Application应用程序要运行,需要Master管理分配调度集群的资源。
2、第二步:
Master接收到TaskScheduler的注册请求之后,会通过资源调度算法对集群资源进行调度,并且与Worker进行通信,请求Worker启动相应的Executor。
3、第三步:
Worker接收到Master的请求之后,会在本节点中启动Executor。因为集群中有多个Worker节点,那么也意味着会启动多个Executor。一个Application对应着Worker中的一个Executor。
4、第四步:
Executor启动完成之后,会向Driver中的TaskScheduler进行反注册,反注册的目的就是让Driver知道新提交的Application应用将由哪些Executor负责执行。
5、第五步:
Executor向Driver中的TaskScheduler反注册完成之后,就意味着SparkContext的初始化过程已经完成,接下来去执行SparkContext下面的代码。
//从linux或者HDFS中获取数据
val lines = sc.textFile("hdfs://tgmaster:9000/in/resws")
//进行单词统计计数
val result = lines.flatMap(_.split(" ")).map((_, 1))
//将计算结果保存到HDFS中
result.saveAsTextFile("hdfs://tgmaster:9000/out/res3")
sc.stop()
6、第六步:
在SparkContext下面的代码中,创建了初始RDD,并对初始RDD进行了Transformation类型的算子操作,但是系统只是记录下了这些操作行为,这些操作行并没有真正的被执行,直到遇到Action类型的算子,触发提交job之后,Action类型的算子之前所有的Transformation类型的算子才会被执行。job会被提交给DAGScheduler,DAGScheduler根据stage划分算法将job划分为多个stage(阶段),并将其封装成TaskSet(任务集合),然后将TaskSet提交给TaskScheduler。
7、第七步:
TaskScheduler根据task分配算法,将TaskSet中的每一个小task分配给Executor去执行。
8、第八步:
Executor接受到task任务之后,通过taskrunner来封装一个task,并从线程池中取出相应的一个线程来执行task。
task线程针对RDD partition分区中的数据进行指定的算子操作,这些算子操作包括Transformation和Action类型的操作。
补充说明:
1、taskrunner(任务运行器),会对我们编写代码进行复制、反序列化操作,进行执行task任务。
2、task分为两大类:ShuffleMapTask和ResultTask。最后一个stage阶段中的task称为ResultTask,在这之前所有的Task称为ShuffleMapTask。
 全国咨询电话:13152008057
全国咨询电话:13152008057




